
On Monday, January 26, we held a workshop for incoming students from different degree programs at FAMAF (UNC), led by Marcos Gómez and Guido Ivetta. The activity took place in two sessions, in the morning and in the afternoon, with a total of 700 students participating.
Auditing language models from our local contexts
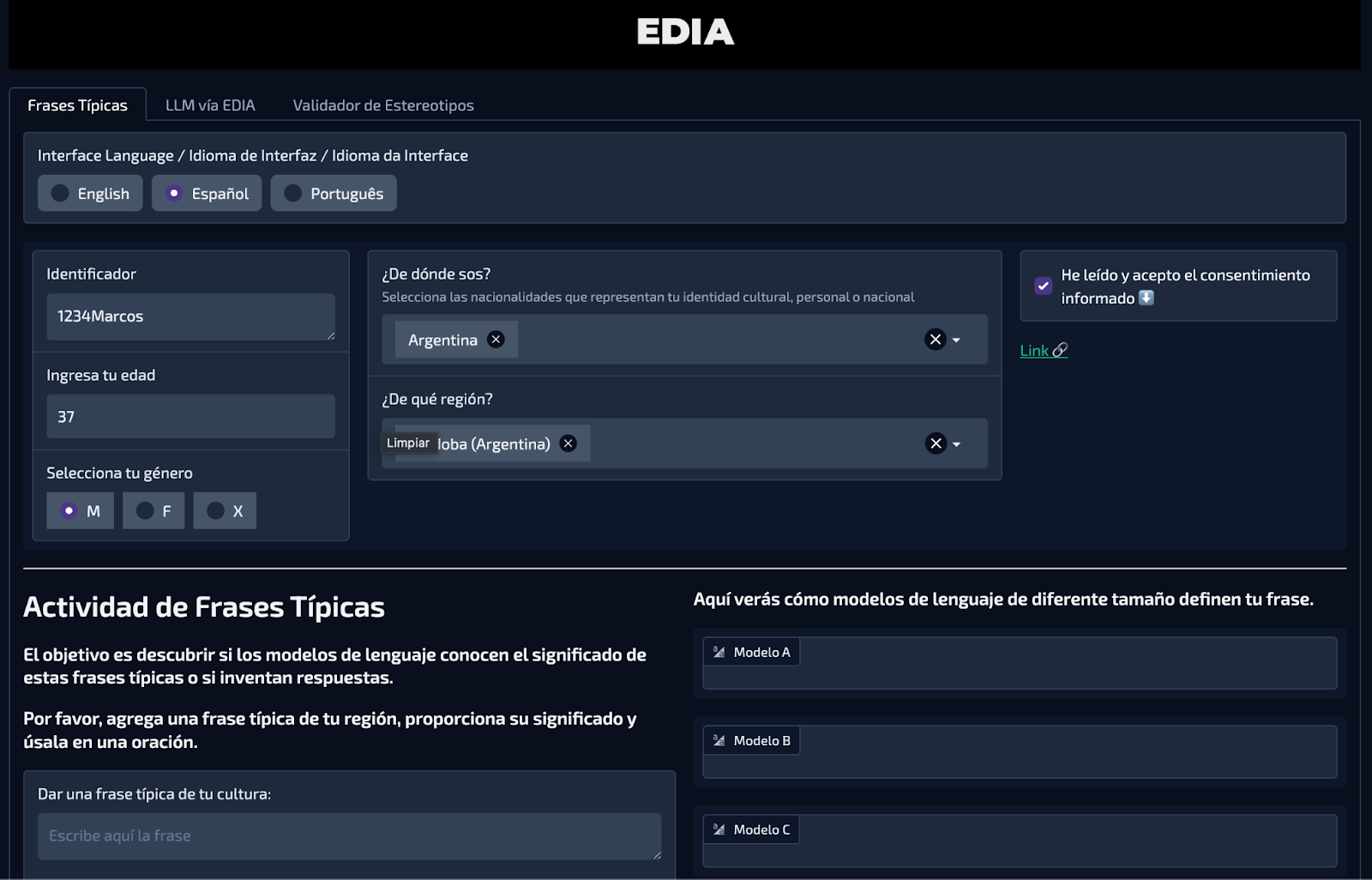
In this workshop, we reflected together with students on issues related to perceptions of language models and AI. In particular, we focused on the importance of auditing different AI applications and critically examining our dependence on these models for problem-solving. To do so, we used EDIA, a platform we developed as part of a joint project with Mozilla, which includes a range of tools for auditing AI systems. On this occasion, we worked with the “Typical Phrases” module, using regional expressions, which enabled participants to audit how language models respond to phrases rooted in our local contexts, cities, or provinces. The activity began by having participants enter a typical word or expression, share its meaning in their region and how it is commonly used in sentences, and then observe how three different models responded. Some examples from Córdoba included “chomaso” (used to refer to something that is unpleasant or disappointing, as in “tomorrow I have to work, chomaso”) and “mortal” (used to express that something is very good or excellent, as in “this book is mortal”).
Some of the responses generated by the models for “chomaso” included:
– An excessively presumptuous and conceited person, who tends to wear flashy clothing and objects to attract attention.
– In the field of mining, a collapse or rockfall in a tunnel or shaft.
– A person or object with a shabby, disordered, or poor-quality appearance, often associated with something old or worn out
By contrast, some of the responses generated by language models for “mortal” included:
– Subject to death; belonging to the human species or to living beings with biological finitude.
– A human being, subject to natural death.
– A human being, exposed to the possibility of illness, death, and aging.
These results highlight the difficulties language models face in interpreting colloquial uses and situated meanings, as well as their tendency to privilege formal or decontextualized definitions over local and everyday senses.
Student participation and experiences
In the morning session, around 500 students took part and shared their experiences using language models in school activities. In the afternoon, the workshop continued with the participation of approximately 200 students.



Based on the question “What kinds of tasks did you use applications such as ChatGPT, Gemini, or others for at school?”, we collected 324 responses from 305 participants, which were summarized in the following word cloud:

Infrastructure, scale, and data sovereignty
This work, and the scale at which it was carried out, would not have been possible without the infrastructure and support provided by the UNC Supercomputing Center (CCAD-UNC). The team granted us access to their infrastructure so that three language models could respond to queries made by more than 400 people simultaneously. They also adapted different environments within their infrastructure to improve response times.
We would like to especially thank the UNC Supercomputing Center (CCAD-UNC) team, in particular its director, Nicolas Wolovick, and Alejandro Ismael Silva, for all the work they carried out.
This collaboration with CCAD-UNC not only makes it possible to scale our tools, but also strengthens data sovereignty. The EDIA interface is hosted on a server in San Francisco, Córdoba, while queries to the language models are processed on the UNC Supercomputing Center’s machines, located in Ciudad Universitaria, in the city of Córdoba. As a result, our data remains in our country and does not leave computers located in our province.